



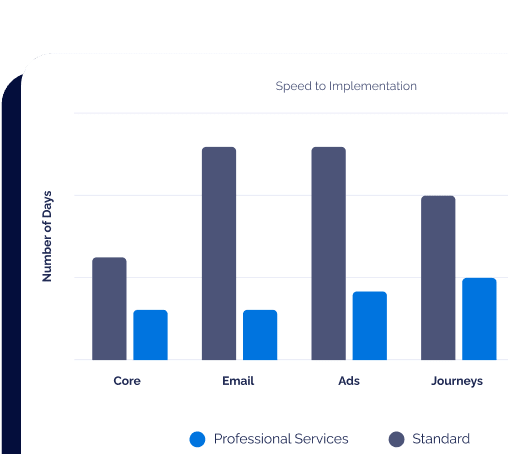


Having a smooth deployment process is paramount for rapid iteration – it allows us to build and test things very quickly, and push out fixes on a moments’ notice. It can also help scale our services up and down as we need more resources. We’ve experimented with a number of different deployment strategies before finally reaching what we feel to be a good balance between fast and stable.
Using Ansible, Packer, and AWS for easy deployment
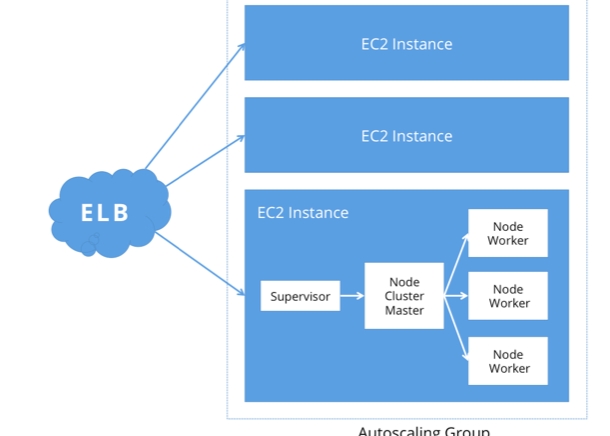
Our main codebase is written in node.js. Because of node’s single-threaded nature, we can better take advantage of the CPU cores we have access to by running several node processes. Node’s cluster module is used to manage and orchestrate the worker processes. The cluster control plane ensures that when a worker goes down, another one is brought back up to replace it. We can also use the cluster control plane to do quick rolling restarts of all its worker processes as needed (on SIGHUP, for example) – much faster than doing a load-balancer-level rolling restart. Sitting in front of our cluster control plane processes is a supervisor process, to ensure node never goes down. Perhaps this is superfluous, but I think the extra load is marginal compared to the potential benefit.
Our entire infrastructure is on AWS, which makes scaling horizontally (and, to some extent, scaling vertically) very easy. We run a number of EC2 instances behind an Elastic Load Balancer, to fairly balance traffic between the instances and to easily scale up, scale down, and bring instances out of commission (for example, to do more comprehensive upgrades). We also make heavy use of AWS’s Auto-Scaling Groups. At its base level, we can use the ASG to ensure to ensure that a quorum of instances is maintained at all times, and to terminate and replace defective instances. We also use ASGs to scale up as needed, using CPU usage as a metric, without manual intervention. No more 3AM provisioning on a PagerDuty alarm!
Ansible and Packer
In order for the ASG’s Launch Configuration to be able to provision a properly-configured new instance quickly, we have custom AMIs for each application, built with Ansible and Packer (Ansible may be overkill for setting up an image with Packer, but it is certainly a much nicer language for expressing server configuration than bash). The AMIs ship with an (at this point) outdated version of our application and dependencies, and contain a startup script that pulls the latest version of the application from git and installs the latest dependencies. Given this, we only need to recreate the AMI when the server configuration changes (e.g., a new package is installed or we want to do a kernel upgrade); code changes can still be served off of the old AMI. Now we can know that whenever a new instance is launched, it will be running the latest production version of the proper service.
Great! Once we’ve gotten this far, doing day-to-day deployments is a piece of cake. To do a routine application deployment, it’s as simple as running a Fabric script which ssh’s in to each server, runs a git pull, re-installs dependencies, and does a rolling restart of the node workers (obviously more complex deployments require more scripting, but 95% of our deployments are this simple). Using Fabric-EC2 , it is incredibly simple to run deployments on a specific subset of our EC2 fleet.
Of course, even doing this is a tedious extra step compared to the bare minimum: git push. We have a simple CI solution set up to automatically run tests on each push and, if tests pass, run the Fabric deployment automatically. This makes most deployments truly headache free (assuming we are deploying working code, which, hopefully, the tests can verify!).
We’ve been through a number of iterations on our deployment techniques, but using this technique we’ve been able to scale our infrastructure while doing rapid deployments (multiple times per day), all with minimal effort.

Provisioning stateless servers is the easy part. Interested in helping us solve the data storage and analysis problem? We’d love to hear from you. [email protected]
Dmitri is a co-founder of Branch Metrics , a full service, deep linking solution for mobile apps. Branch links have the power to deep link through app install and open, allowing the app developer to deliver a personalized post-install experience. Branch links can be used to build full user-to-user referral programs with automatic install attribution and rewarding, or for automatically deep linking to content post-install. Also, the Branch analytics dashboard gives insights into where organic installs are coming from, as well as interesting metrics like install conversion funnels and k-factors of growth features.